

The Default Settings Will Not Save You
The Global Experiment You Didn’t Ask For

A few months ago you asked a question to one of your favorite models and the answer was good, you were impressed, then you did it again and you noticed it was getting much better, new models were more accurate and a lot faster, and as the responses got more accurate you moved on faster.
Weeks later, you notice you don't reason through those things anymore. You didn't decide to stop. The shortcut became the default. The output stayed high. The thinking quietly disappeared.
What matters here is not AI in general. It’s how it’s actually being used: by default, at scale.
Right now, TODAY, before the killer robots and the cure of all diseases, we do have a new problem we are not addressing.There is already an emerging body of research pointing to early but consistent signals of cognitive cost, overreliance, and effects on memory from AI use. The findings are suggestive, not yet conclusive, but the direction is clear and the pattern is repeating across studies.
This isn’t an accident. It’s a predictable consequence of how these systems are designed.
The Research
Before I give you a summary of what is going on I need to give you some context that might annoy you a bit. I reviewed 30 studies so far and very few describe their AI configuration in any detail. Zero studies provide comprehensive documentation of AI parameters such as temperature, system prompts, or specific model versions beyond the base name. This pattern has a critical implication: the negative cognitive effects documented in this literature overwhelmingly reflect default AI use.
Now let’s see what some of the research says:
Michael Gerlich surveyed and interviewed 666 people across ages and education levels and found a clear pattern: the more frequently someone used AI tools, the lower they scored on critical thinking measures. Younger participants were hit hardest, higher dependence, lower scores. The study doesn’t tell us how large the gap is (no standardized effect sizes), but the direction held across every subgroup (Gerlich, 2025, Societies).
Other studies point to a memory cost. Bai, Liu & Su (2023) reviewed the emerging evidence and concluded that while ChatGPT makes learning more accessible, extended reliance risks reducing long-term retention. A University of Pennsylvania study put a number on it: students using ChatGPT to practice solved 48% more problems correctly, but scored 17% lower on a test of actual concept understanding (Barshay, 2024). Akgun and Toker (2024) found something more specific: when students had to commit to an answer before seeing what the AI said, they retained more. Without that friction, memory declined the longer they used the tool.
An MIT Media Lab team took this further by looking at what’s happening in the brain. Nataliya Kosmyna and colleagues used EEG to monitor 54 people across four sessions as they wrote essays, one group using ChatGPT, one using a search engine, one using nothing. The ChatGPT group showed the weakest brain connectivity of the three. When asked to rewrite their essays without the tool, 83% couldn’t recall what they’d written. The study is a preprint, not yet peer-reviewed, and EEG has real limitations in spatial resolution but the authors coined a term worth holding onto: “cognitive debt,” the long-term cognitive costs that accumulate from short-term reliance on AI (Kosmyna et al., 2025).
See this Google Sheet for additional research, links, sources and commentary. I’ve summarized key studies here for brevity, you can dive deeper there for full details.
Three insights stand out from the research:
Design Is Destiny: The same underlying technology produces opposite cognitive outcomes depending on whether it gives answers (harmful to learning) or gives hints (neutral or beneficial). This means the cognitive effects of AI are not inevitable properties of the technology but choices made by product designers.
Individual differences matter greatly: Need for cognition, metacognitive sensitivity, prior expertise, and age all moderate whether AI use helps or harms. The people most vulnerable to negative effects are precisely those who might benefit most from AI assistance: younger, less experienced, and less metacognitively aware users.
The confidence-competence gap is the most dangerous pattern. Multiple independent studies find that AI use increases confidence while decreasing actual capability, creating a condition where users are simultaneously less competent and less aware of their incompetence. This combination echoes the Dunning-Kruger effect, now amplified by technology that provides sophisticated-sounding outputs regardless of their accuracy.
One caveat. Cognitive offloading to tools has accompanied every major technology shift (writing, printing, calculators, GPS) and in most cases freed cognitive resources were redirected to higher-order tasks. AI may follow the same pattern. But previous tools didn’t actively increase users’ confidence in the very abilities they were eroding. That combination of declining competence paired with rising confidence is what makes the early signal worth taking seriously.
If longitudinal studies show that sustained AI users maintain equivalent unaided performance on tasks they’ve offloaded, this concern is misplaced and the historical pattern holds. However, we don’t have those studies yet, and we’re unlikely to get them without more attention and funding directed at the early evidence.
The Scale
There is no public data on how many users configure system instructions, but the scale and structure of usage make the baseline clear. ChatGPT alone reaches roughly 900 million weekly users, with Gemini adding hundreds of millions more. Around 94-95% of these users are on free tiers, where customization is minimal and defaults govern the interaction. Even if tens of millions of users experimented with configuration, which is likely an overestimate, they would still represent a small fraction of the total population. The dominant mode of AI use, by orders of magnitude, is unconfigured.
Right now, hundreds of millions of people are interacting with these systems in their default configuration, without instructions, constraints, or deliberate control. At that scale, defaults don't stay neutral. They become the environment in which people think, decide, and learn.
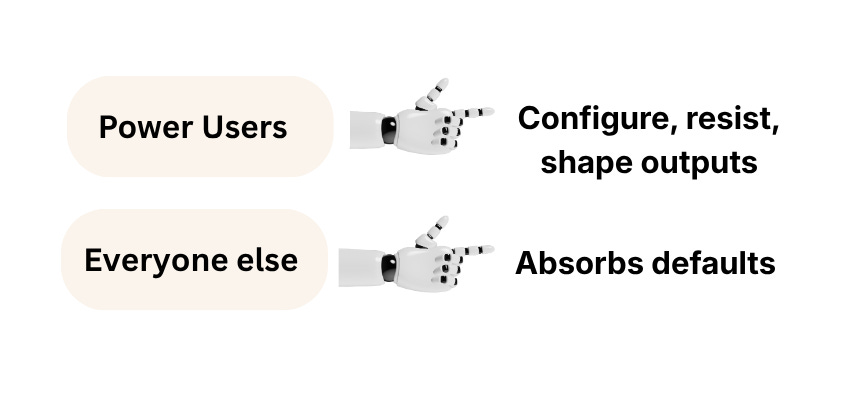
The AI inequality is becoming structural.
If you’re thinking ‘this doesn’t apply to me, I know how to use AI without any of the downsides,’ you sound like the person who says ‘I’m intelligent enough, advertising doesn’t persuade me.’ In communication research, this is called the third-person effect: the consistent finding that people believe media and persuasion influence others but not themselves. Even if you believe this is not affecting you, please at least consider the impact on your friends, family and community.
What Can You Do?
You are not going to be happy about this but here we go. Today you can set highly adversarial system instructions for your account, create projects with dedicated instructions that function as guardrails, and build a series of validation skills that trigger at different points of decision-making. You can also create an external memory that updates itself and allows you to share context between models, so switching cost stays low. I will be sharing my own setup soon.
Shaping the architecture of your account is one way to influence and “control” your AI interactions; however, OpenAI and other providers do not offer clear, centralized documentation on how different levels of instructions interact, what overrides what, and where your input actually sits in the hierarchy. This is a problem on its own but I’ll address that in another post.
From the scattered documentation, the general picture is: system instructions override everything below them, project instructions override user prompts, and user prompts only operate within those constraints.
A caveat, this hierarchy applies primarily to ChatGPT’s architecture. Other platforms handle it differently. Anthropic’s Claude, for instance, gives the user’s system prompt a different role relative to its own built-in guidelines, and Google’s Gemini structures priority in its own way.
The core principle holds across platforms (some instructions carry more weight than others) but the specifics vary. This matters because if you’re going to build a protocol that shapes your AI usage behavior, you need to understand where your levers actually are and AI companies are not making that any easier. Transparency about how your input interacts with their system has never been the business model.
Let’s say you are tech savvy enough and went deep and created your own guardrails. Unfortunately, even though this helps significantly, it doesn’t solve the problem entirely. And it gets worse when you think about the broader population.
The risk is not that AI replaces thinking. It’s that default usage at scale increases reliance while increasing confidence, which weakens independent judgment.
We Need To Refocus The Conversation
We have to move on from the binary view that there are only 2 ways to see the advancement of AI, either we’re all gonna die or the abundance will be so vast that we will be happily skipping towards our hobbies. The messy and dangerous middle is already here.
The public conversation continues to stay abstract: “As a society we will need to figure out how to deal with the consequences of AI.” Who is this society lady, when is she going to start working on this?
I’m thinking about my elderly parents, the new generations, and everybody in between, people who feel they need to get on board with these tools to survive the future, yet are giving away one of our most precious capacities.
The ability to discern.
👉 P.S. The next post will cover the mechanisms behind the potential loss of judgment. If this made you uncomfortable, share it. Awareness is the first step and it doesn’t scale without you.