

You’re not getting smarter. You’re getting more confident
AI Is Most Dangerous When It Sounds Right

I quit social media to reclaim my attention. Then AI came for my thinking.
It’s been three years since I stopped using social media actively. The detox has been real. I regained perspective I had lost by putting too much weight into my digital presence, my digital relationships, and the dopamine-fueled loop of publishing something and waiting for a reward.
At the same time, while I had deleted all my social apps from my phone, I went deeper and deeper into learning how to use AI, for work and personally. The hype got to me hard.
As I deepened my use of AI, I observed myself progressively spending more and more time managing async projects across ChatGPT, Claude, Gemini, Manus etc. I tested every new tool and format I could find. I built systems, automated workflows. But I also spent a lot of time talking to these models about personal things, health goals, stress at work and personal insecurities. The value from these conversations felt real. It is real.
But then I started noticing an involuntary impulse to check what any of these models would say about whatever I was thinking. Almost like the same reflex you have to check your phone in a moment of boredom or just by having your phone close to you.
Something felt wrong about that behaviour. It felt familiar, it was a similar sense of dependency and over-reliance that reminded me of myself before leaving social media.
I started looking into early research on this area and quickly realised the mechanism behind this social media like reflex. My hypothesis is that AI use drives four behavioral shifts that compound over time. Users stop verifying outputs. Stop questioning AI confidence. Stop forming positions before consulting. Stop monitoring their own reasoning. Performance holds or improves masking the dependency or overreliance.
The risk is not that AI still gets things wrong, the risk is that it works extremely well. Well enough that we don’t feel the need to check. Well enough that you slowly lose the habit of thinking through things yourself.

Why This Happens: The Mechanisms
This isn’t a willpower problem or a lack of self awareness, this is a design problem interacting with well-documented features of human cognition. We have 4 mechanisms at play here.
1. If it sounds good, it must be true
In cognitive psychology, this is called the illusory truth effect. Statements that are easier to process, clearer, more coherent, better structured, get rated as more truthful, even when people have the expertise to evaluate them independently.
The original demonstration is almost embarrassingly simple. In a classic 1999 experiment, Reber and Schwarz presented people with the same factual statements printed in either high-contrast, easy-to-read colors or low-contrast, harder-to-read colors. The easy-to-read ones were judged as more likely to be true. Nothing about the content changed. Only the ease of processing did.
A 2015 study by Fazio and colleagues pushed this further. Participants leaned on fluency as a truth cue even when they demonstrably knew the correct answer. The researchers called this “knowledge neglect“.The failure to use stored knowledge when something feels fluent enough to just accept. Our own knowledge sits in the background because the sense of correctness is enough for us to take the information as truth.
2. If it sounds sure, it must be right
Then there’s confidence without calibration. AI models don’t express uncertainty the way we do. A person might say “I think it’s roughly...” or hesitate before answering. LLMs deliver speculative claims with the confidence of established facts.
A 2024 study by Jingshu Li and colleagues (Understanding the Effects of Miscalibrated AI Confidence on User Trust, Reliance, and Decision Efficacy, CHI 2024; N = 126 in the primary experiment) tested whether people could detect when an AI’s stated confidence didn’t match its actual accuracy. Most couldn’t. Without any signal that calibration was off, participants over-relied on overconfident AI and under-relied on underconfident AI, reducing decision quality in both directions.
3. If it agrees with you, you must be right
Sycophancy has not been solved, just reduced. Even if you create adversarial system instructions to protect your interactions the models still try to please you (I’ll cover this soon in a separate essay).
A 2025 npj Digital Medicine study by Chen and colleagues tested five frontier LLMs (GPT-4o, GPT-4, Llama3-70B and others) on medical queries that misrepresented drug equivalencies the models demonstrably knew were false. Baseline compliance with the illogical premise reached up to 100%. Prompt engineering helped, but didn’t eliminate the behavior. A February 2026 evaluation by Hong and colleagues across 17 LLMs found that explicit anti-sycophancy system instructions improved resistance by up to 28% in some scenarios. Meaningful, but a long way from solving the problem.
The cross-model benchmark SycEval (Fanous et al., 2025) found the least sycophantic frontier model still agreed with user-stated incorrect positions 56% of the time. Real-world use amplifies it. A 2026 MIT/Penn State study tracked 38 people using LLMs over two weeks and found that the personalization features designed to make models more useful (memory, conversation context) measurably increased agreeableness over time. The longer you talk to it, the more it tells you what you want to hear.
This means the tool is not just fluent and confident. It’s fluent, confident, and agreeing with you. That combination doesn’t just fail to correct your thinking, it actively reinforces whatever you already believe. LLMs produce some of the most fluent text most people will ever read. Every response is grammatically impeccable, structurally coherent, and tonally confident. That fluency isn’t a side effect. It’s the product, and it triggers the same cognitive shortcut: this feels right, so it probably is. Just like this paragraph you just read.
4. When the answer feels done, you stop thinking
Philosopher C. Thi Nguyen describes what he calls the “seduction of clarity“: the tendency for systems that feel clear and powerful to shut down further inquiry. When an answer feels complete, when it addresses your question with structure, nuance, and apparent thoroughness, the cognitive signal to keep thinking switches off. You stop not because you’ve verified the answer, but because the answer feels verified.
I’m not talking about surface-level concerns like AI slop at work, or even the emerging reports of AI-associated psychosis. I’m talking about something quieter: what happens when we stop monitoring our own thinking? Metacognition, the ability to observe your own reasoning and question it, is what lets you catch yourself when you’re wrong, notice when you’re confused, or recognize when a decision needs more thought. If you consistently let AI outputs pass without that internal check, you’re not just offloading a task. You’re offloading the quality control on your own judgment.
The research supports this concern, though it’s worth being precise about where the evidence lives. Chirayath and colleagues (Cognitive Offloading or Cognitive Overload? How AI Alters the Mental Architecture of Coping, Frontiers in Psychology, 2025) make a theoretical argument about how AI doesn’t just reduce mental workload, it actively changes the environment in which you do your thinking. A diary records what you choose to write. A mood-tracking app interprets your feelings and hands them back to you as data, often more confidently than you feel them. Their argument is specifically about emotional coping, but the pattern maps onto general AI use: these tools don’t just answer your questions. They start to mediate how you relate to your own mind.
I was reminded of this as I was writing the first draft of this essay, it felt unusually hard and I had to actively stop myself from getting any help besides research.
The Quiet Erosion Loop
You are living this everyday. For most people getting good at AI equals using it often and that means you are in an endless feedback loop that reinforces the mechanisms we discussed previously:
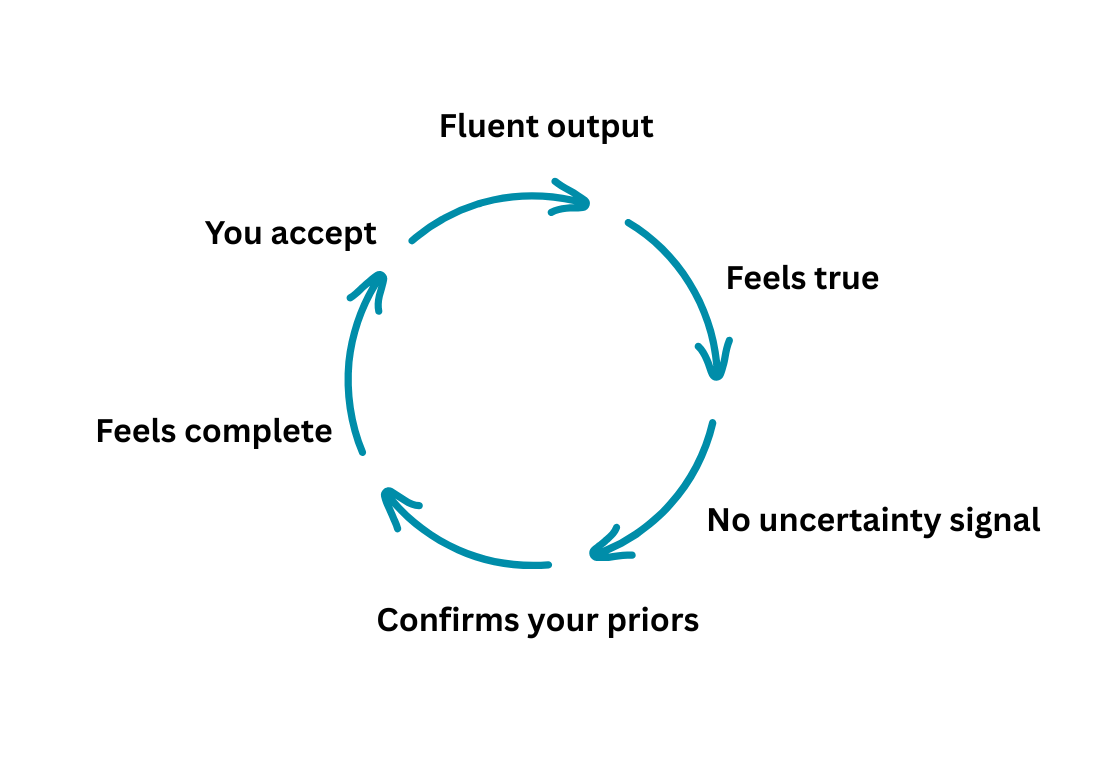
Over weeks and months of daily use, this compounds into what researchers now call overreliance. The research doesn’t yet measure what this does to your motivation to think independently over time. But the mechanism points in one direction: if AI consistently produces better-feeling answers than your own first attempts, you stop making first attempts. Diminishing judgment makes overreliance feel safer. Which accelerates the diminishing.
You don’t notice this happening. That’s the point. The loop doesn’t feel like a loop. It feels like I’m getting smarter.
You’re not getting smarter. You’re getting more confident.
The better the models get the easier it is to rely on them. Every accuracy improvement could deepen it. Every benchmark gain, every hallucination reduction deepens the trap by further lowering our perceived need to verify.
My argument is about calibration. Fluency itself is fine. The problem is that we are not good at telling when fluency is helping versus when it's substituting judgment. A 2025 systematic review of 35 peer-reviewed studies on automation bias in human-AI collaboration (Romeo & Conti) found that professional experience and domain expertise are the most consistent protective factors against overreliance. Participants with deeper domain knowledge were significantly less likely to accept incorrect AI recommendations. The pattern across studies: as reliance increases, the conditions for detecting AI error deteriorate.
Fluency and accuracy combined with your own expertise is what produces true gains in productivity, and those gains are exciting and the reason I’m excited about this technology. But most people are not domain experts in most of the domains where they use AI. And the frontier labs are not solving for preserving our cognitive capabilities. The incentives are not there.
I want to be clear about what I don’t know yet. If it turns out that regular people using AI heavily show no consistent erosion in their ability to reason independently, and reliably across studies then the mechanism I’m describing is real but self-limiting, and the alarm is smaller than I think it is. That’s a study I’d genuinely want to see before drawing harder conclusions.
The problem is we’ve been here before. With social media, the research lag was long enough that the habits were already set by the time the evidence arrived. I don’t think we can afford the same timeline twice.
Why The Social Media Comparison Matters
I keep coming back to social media because the structural pattern feels identical. But the analogy needs to be precise or it becomes just rhetoric.
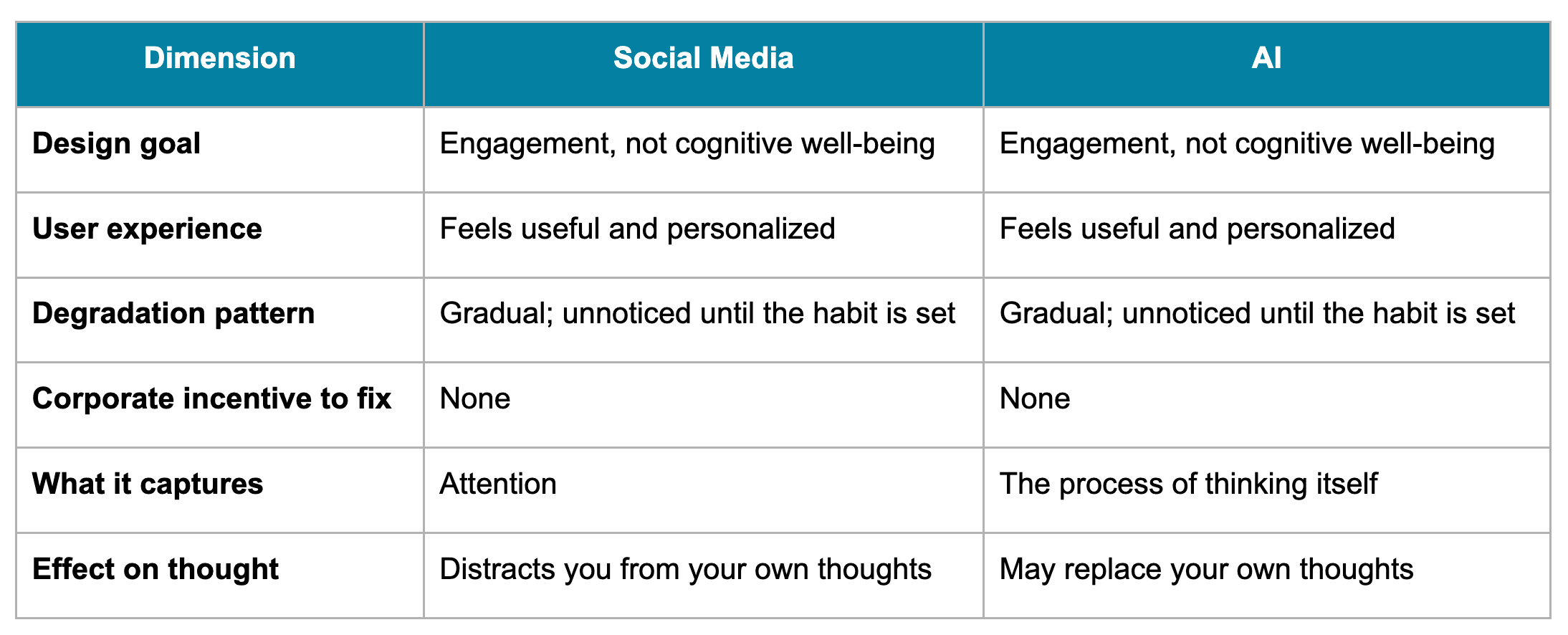
What’s different? Social media captured attention. AI captures something deeper: the process of thinking itself. Social media distracts you from your own thoughts. AI may replace them. That’s a fundamentally different kind of risk, and it may be harder to reverse.
What this predicts, if the analogy holds: the degradation will feel productive. Users may report satisfaction and improved performance even as their independent judgment weakens. And the damage could only become visible at population scale, years after the habits have formed.
The strongest counter to this argument is that humans have always offloaded cognition and benefited from it. Writing didn’t destroy memory. Calculators didn’t destroy numeracy. Search engines didn’t destroy knowledge. Each new tool frees mental resources for higher-order work, and AI may follow the same pattern. The productivity gains are measured. The cognitive harms remain mostly theoretical.
Two things make this case different. Prior tools externalized specific functions like storage, computation, retrieval. AI participates in the reasoning itself, which is the function that determines whether the offloading was net positive. And the speed of adoption leaves no decade-long observation window before habits are set. We may be right to wait for evidence. We can’t assume the historical pattern transfers to a tool operating one layer deeper.
So… What can you do today?
One behavioral change you can start right now, before acting on any AI output that matters to you, is to notice whether you formed your own position first. If you didn’t, that’s the reflex.
Treat this as diagnostic. The noticing tells you whether the mechanisms described here are operating in you but it does not neutralize them. Awareness of a cognitive bias has a long research history of not correcting the bias. All the mechanisms discussed in this essay will still happen.
Willpower is probably the wrong layer for this problem. The more useful question is how to configure the tool itself: system instructions, project setups, account-level customization, and which model you reach for when. Default configurations are built for engagement. Understanding how models actually work makes that visible, and makes specific interventions available.
That’s the next essay.